




 HOME
HOME
 Past Projects
Hardware Perceptron Systems
Training with Evolutionary Algorithms
Hardware Acceleration
Past Projects
Hardware Perceptron Systems
Training with Evolutionary Algorithms
Hardware Acceleration
The analog neural network chip HAGEN is trained with evolutionary algorithms. Two very important parameters to determine the best physical implementation of the algorithm are network size and speed. Within the distributed system several network chips can be used in parallel to increase the maximum size. The topic of this page is how to increase the speed.
The network chip knows two operating modes: First, during configuration, the synaptic weights are written. In terms of the evolutionary algorithm, a new individual is transferred to the chip. Second, in operating mode the test data is presented and - after having been processed by the network - the result data is read and evaluated. The chip is designed for high-speed applications. Its maximum configuration mode data rate is about 600 MByte per second, while in operation mode 1.3 GByte can be transferred per second.
Most likely, a pure software implementation would not be able to cope with that speed, particularly a software running on the embedded PowerPC. Therefore, a programmable hardware acceleration was developed to use the chip at its maximum speed.
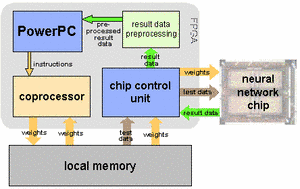
All data transfer to and from the chip is organized by a chip control unit implemented in the FPGA (for more information about the physical hardware structure follow this link: Distributed HAGEN). The synaptic weights and the test data used in operation mode are read from the local memory and written directly to the neural network chip. To produce new offspring at the necessary rate, an evolutionary coprocessor was developed. Its design pursues three aims: First, it must be fast enough to cope with the neural network's speed. Second, it should be completely controlled by software instructions and third, it should be able to carry out a wide range of conceivable evolutionary algorithms. For a detailed description of the coprocessor please have a look at 'Speeding Up Hardware Evolution: A Coprocessor for Evolutionary Algorithms' in the publications area. By using four parallel data pipelines the coprocessor is able to generate new individuals, by utilizing programmable crossover and mutation operators, at a rate of 640 MByte per second.
Another issue is the fitness calculation. Depending on the given problem, it might be quite costly in terms of data rate and computing power; but, unlike the evolutionary operators which are similar for different tasks, the fitness function is highly problem dependent. Therefore a standardized fitness calculation is not available. It is planned to preprocess the result data from the chip in customized logic to reduce the amount of data the PowerPC has to handle.
With all the computational costly operations carried out in hardware, the software running on the embedded PowerPC has to execute the high level parts of the training algorithm only. Nevertheless, it can use the neural network chip at maximum speed.
